

4
A practical guide to search engine indexation
Why is indexation important?
For a web page to be ranked and gain SEO value in search engine results it has to be indexed first, even before we optimise the content fit the modern SEO factors. The indexation is only possible after a successful crawl of the website by so called search engine crawlers (or spiders). It is important to know how to develop and configure a website correctly, to ensure that it will be fully indexed.
Typical causes of indexation issues
Unintended blocking of pages with noindex, nofollow robots meta tag
Noindex meta tags are placed in the header of a page and can be used to block a page from being indexed by a search engine. This can make sense for pages that include duplicate content or other specific information that does not require to be indexed. However it can also happen that noindex tags are implemented unintended on pages that are valuable and therefore should be indexed.
Mistakes in robots.txt
The robots.txt files are used to tell search bots which areas of a website they can crawl and which not. This can be used to optimise the crawl budget if a site has too many pages to index all of them. Since this file has a big impact on indexation it is also one of the main sources of problems that occur with indexation and should therefore always be checked first. A mistake in the robots.txt file can block a web page from being indexed accidentally.
Duplicate content
Search engines do not want to index the same content twice so when crawlers discover duplicate content on a website, indexation typically goes down. As a consequence of duplicate content on a page, it can happen that a whole part of a website is not indexed. Also pages that have very similar content or do not have any unique characteristics such as title tags, and headings can accidentally be seen as duplicate content by search engines.
Crawl anomalies & error pages (e.g. 404 – not found, 500 – Internal server error)
A crawl anomaly occurs when search engines receive a server response in the 4xx- and 5xx-level, that is not listed in the coverage report. A crawl anomaly can be caused by the server, the DNS configuration or the content management system. Generally it means that the search engine can not access the page that it is requesting and therefore stops trying. If this issue appears on important pages it could also lead to partial indexation of the entire website.
Example
A pages provides search engines with a server side error status (e.g. 500), which means that the content cannot be accessed and these pages won’t be indexed. If it’s already indexed it could also mean that it will be removed from the index.
Heavy use of JavaScript in Progressive Web Applications (PWA)
Modern applications rely heavily on JavaScript. Unfortunately, the process of crawling a web page with JavaScript is more complicated for a search engine. Therefore there are many things that can go wrong while a search engine bot is trying to index a web page. It also takes more time to render JavaScript files which poses another problem because search engines do work with crawl budgets which optimises the time they spend to index a specific page. Yet another problem can be that a search engine bot does not fetch a JavaScript file because it is not necessary from a rendering point of view.
Indexation audit – How to spot errors and monitor your SEO indexation?
Coverage reports in Google Search Console (GSC)
GSC provides an index coverage status report that gives information about, which pages have been indexed and lists URLs that have caused any problems, while Google has tried to index them.
The following screenshots display the coverage report from an example website. As you can see, Google shows a graph with the number of URLs that have caused an error and also the number of different issues identified.
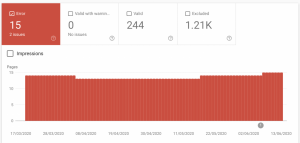
GSC provides a document for troubleshooting when there are increases in errors or warnings for its users.
GSC also enables the user to see information about what the specific errors are and how many URLs are affected by that problem.
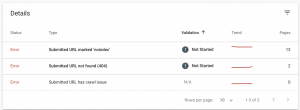
By clicking on a specific error, a graph with the pages affected by the error over time as well as their URLs are illustrated.
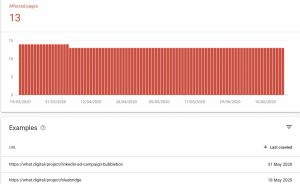
In this case, this is the details page for all of the URLs responding with noindex. Each details page has a “Learn More” link to a Google documentation page that includes information about the specific error. Furthermore Google provides tools to inspect each URL individually and test if the page is blocked by the robots.txt.
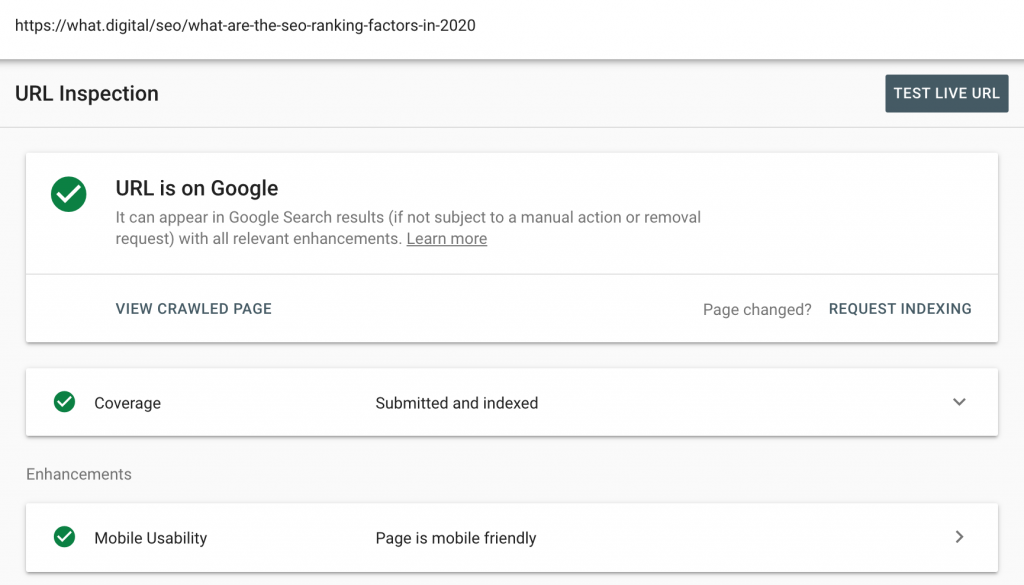
Inspect URL in GSC
Inspecting URL in GSC is probably the best tool to deep dive into the indexation issues. GSC gives a detailed report on the current status of the page and you can also Test Live URL, which will then access and render the page. That’s particularly useful for validating the indexation of PWA pages.
A custom crawl with screaming frog
Screaming frog is an audit tool that crawls a website just like a search engine does and while doing this it gathers on-page data. Its purpose is to then deliver information in an understandable and usable way to the marketer. By finding many different kind of errors (e.g. server and link error, redirects, URLs blocked by robots.txt) it does also support the user by identifying any issues that can cause indexation problems. Screaming frog can also conduct a crawl of pages that need to rendered (i.e. PWA/JavaScript), but we found this feature to be still a bit unreliable.
How to get indexation right
Monitor and understand indexation issues
First of all ensure you study the coverage reports in GSC to understand all relevant issues that cause incomplete indexation. We’ll look at some of the most common fixes.
Create a complete sitemap file
Ensure your XML sitemap file is complete and added to GSC. The sitemap should contain ALL URLs that you want to get listed on Google. This will be your reference point in terms of important pages.
Provide a valid robots.txt
All pages that aren’t listed in your sitemap should be blocked from search engines, this could include filtered content on e-commerce site, tags pages or other example of potentially duplicate content pages. Robots.txt file is the most effective method to block search engines from accessing these unwanted pages.
Be careful when editing and creating robots.txt file. First the URL has to be checked and clarified if it is supposed to be blocked. If the page is blocked on purpose, it can be removed from the sitemap. If the page is not supposed to be blocked, then the rules on the robots.txt file have to be analysed and the one that is blocking the page has to be found and rewritten.
Fix pages with noindex, no follow tags
In case you can’t use robots.txt file to block unwanted pages (e.g. no access to the server etc.) you can use the noindex,nofollow tag to stop search engines from crawling these pages. This can be done by changing the web page manually or applying some rules in your CMS by switching the page from noindex to index.
Provide unique content and optimise important tags
In case of indexation issues related to duplicate content the best method to improve indexation is to make the content unique or at least provide different meta tags for every page. This helps search engines to recognise these pages as unique. A pages content should be of high quality and unique, content that is copied or of very low quality might end up not being indexed.
There are also cases on large websites when content does not get crawled and indexed because it is too deep within the sites architecture. In those cases it’s recommended to improve internal linking, change website architecture, ensure these pages are listed in the sitemap and also use structure data.
Control your URLs and avoid server side issues
Ensure you provide the right status code to search engines crawlers, i.e. 200 for pages that should be indexed, 404 for pages that should be removed and 301 for pages that have been redirected. There aren’t really other valid server status codes that should be used.
Request indexing in GSC
In cases of crawl anomalies or indexation issues it’s recommended to inspect individual URLs and deal with the root cause. It is also possible that the problem was only temporary, Google offers therefore tools like “Fetch as Google”, to check if the Googlebot is currently able to crawl the page. For diagnosing a specific error, Google offers a list of different tools that are available in GSC. Once you’ve identified and rectified the problem you can request immediate indexing of the affected page.
Avoid JavaScript and use server-side rendering if possible
There are certain steps to take to make it easier for a search engine to read a page that includes JavaScript. Basically there are three areas that have to be addressed in this process, crawlability (prober structure of the website), renderability (the website should be easy to rendered for search engines) and crawl budget, which is mostly affected by page speed. There are tools like the URL Inspection Tool that help to check if a specific website fulfills these criteria. In case there are any issues, the website can be improved by the information provided from these checks. Something important to know is that search engines do have issues with client-side rendering, but they usually work well with server-side rendering. For this reason, implementing client-side rendering alongside with dynamic rendering, which is officially supported by Google can support the SEO of a website.
Browse other related SEO topics in our complete 2020 SEO guide.