

Ein Praxis-Guide zur Suchmaschinen-Indexierung
Warum ist Indexierung wichtig?
Damit eine Website in den Suchergebnissen gerankt wird und dadurch einen gewissen SEO-Wert erzielt, muss sie zunächst indexiert werden – noch bevor der Content nach modernen SEO-Faktoren optimiert wird. Die Indexierung ist nur nach einem erfolgreichen Crawlen der Website durch sogenannte Suchmaschinen-Crawler (oder Spider) möglich. Um sicherzustellen, dass die Website auch vollständig indexiert werden kann, ist die richtige Entwicklung und Konfigurierung von grosser Bedeutung.
Typische Ursachen für Indexierungsprobleme
Unbeabsichtigtes Blockieren von Seiten mit den Meta-Tags noindex, nofollow, robots
Noindex-Meta-Tags werden in der Kopfleiste einer Seite platziert und können dazu verwendet werden, die Indexierung einer Seite durch eine Suchmaschine zu blockieren. Dies kann für Seiten sinnvoll sein, die Duplicate Content oder andere bestimmte Informationen enthalten, die nicht indexiert werden müssen. Es kann jedoch auch vorkommen, dass Noindex-Tags unabsichtlich auf wertvollen Seiten implementiert werden, die eigentlich indexiert werden sollten.
Fehler in robots.txt
Die robots.txt-Dateien dienen dazu, Such-Bots mitzuteilen, welche Bereiche einer Website sie durchsuchen können und welche nicht. Dies kann nützlich für die Optimierung des Crawl-Budgets sein, wenn eine Website zu viele Seiten enthält, um sie alle zu indexieren. Da diese Datei grossen Einfluss auf die Indexierung hat, ist sie auch eine der Hauptquellen für Probleme, die bei der Indexierung auftreten können und sollte daher immer zuerst überprüft werden. Ein Fehler in der robots.txt-Datei kann eine Website ungewollt daran hindern, indexiert zu werden.
Duplicate Content
Suchmaschinen wollen denselben Content nicht zweimal indexieren. Wenn also Crawler Duplicate Content auf einer Website entdecken, wird die Indexierung im Normalfall abgebrochen. Aufgrund dessen kann es vorkommen, dass ein grosser Teil einer Website nicht indexiert wird. Auch Seiten, die sehr ähnlichen Content beinhalten oder keine eindeutigen Merkmale wie Titel-Tags oder Überschriften aufweisen, können von Suchmaschinen fälschlicherweise als Duplicate Content erkannt werden.
Crawl-Anomaliern & Fehlerseiten (z.B. 404 – not found 500 – internal server error)
Eine Crawl-Anomalie tritt auf, wenn Suchmaschinen einen Server-Antwort im 4xx- und 5xx-Bereich erhalten, die nicht im Coverage Report aufgeführt ist. Dabei kann die Crawl-Anomalie durch den Server, die DNS-Konfiguration oder das Content Management-System verursacht werden. Im Allgemeinen bedeutet dies, dass die Suchmaschine nicht auf die angeforderte Seite zugreifen kann und deshalb den Versuch abbricht. Wenn dieses Problem auf wichtigen Seiten auftritt, ist die Folge eine unvollständige Indexierung der gesamten Website.
Beispiel
Eine Seite liefert Suchmaschinen einen Server-basierten Fehlerstatus (z.B. 500), was bedeutet, dass auf den Inhalt nicht zugegriffen werden kann und diese Seiten folglich nicht indiziert werden. Wenn die Seite bereits indiziert ist, könnte dies auch bedeuten, dass sie aus dem Index entfernt wird.
Massive Verwendung von JavaScript in Progressive Web Applications (PWA)
Moderne Anwendungen sind stark auf JavaScript angewiesen. Leider erschweren Websites mit JavaScript Suchmaschinen den Crawl-Prozess, was zur Folge hat, dass vieles bei der Indexierung einer Website durch Suchmaschinen-Bots schiefgehen kann. Es dauert ausserdem länger, JavaScript-Dateien zu rendern, was wiederum ein Problem für das Crawl-Budget darstellt, das für die Zeit-Optimierung der Indexierung einer Seite wichtig ist. Ein weiteres Problem kann darin bestehen, dass ein Suchmaschinen-Bot keine JavaScript-Datei abruft, weil dies aus Rendering-Sicht nicht notwendig ist.
Indexierungs-Audit – Wie du Fehler erkennst und deine SEO-Indexierung überwachst
Coverage-Reports in der Google Search Console (GSC)
GSC bietet einen Statusbericht der Index-Coverage, der Auskunft darüber gibt, welche Seiten indiziert wurden und jene URLs auflistet, die Probleme bei Googles Indexierungs-Versuch verursacht haben.
Die folgenden Screenshots stellen den Coverage-Report einer Beispiel-Website dar. Wie man erkennen kann, zeigt Google ein Diagramm mit der Anzahl der URLs, die einen Fehler verursacht haben sowie die Anzahl der unterschiedlichen Probleme, die identifiziert wurden.
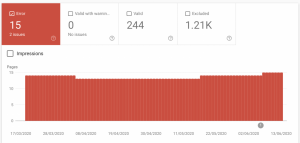
GSC stellt ein Dokument für Troubleshooting zur Verfügung, wenn es es zu einer Zunahme von Fehlern oder Benutzer-Warnungen kommt.
Ausserdem ermöglicht GSC dem Benutzer, Informationen über die spezifischen Fehler und die Anzahl der betroffenen URLs zu erhalten.
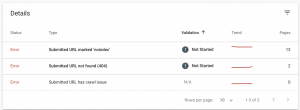
Durch Anklicken eines bestimmten Fehlers erscheint eine Grafik, die die von dem Fehler betroffenen Seiten über einen längeren Zeitraum anzeigt sowie deren URLs beinhaltet.
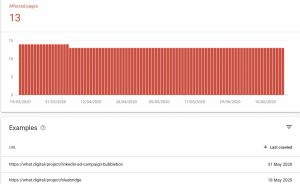
In diesem Fall wird die Detailseite für alle URLs, die mit noindex antworten, angezeigt. Jede Detailseite ist durch einen „Erfahren Sie mehr“-Link mit einer Google-Dokumentationsseite verbunden, die Informationen zu dem jeweiligen Fehler enthält. Darüber hinaus stellt Google Tools zur Verfügung, um jede URL einzeln zu überprüfen und zu testen, ob die Seite durch robots.txt blockiert ist.
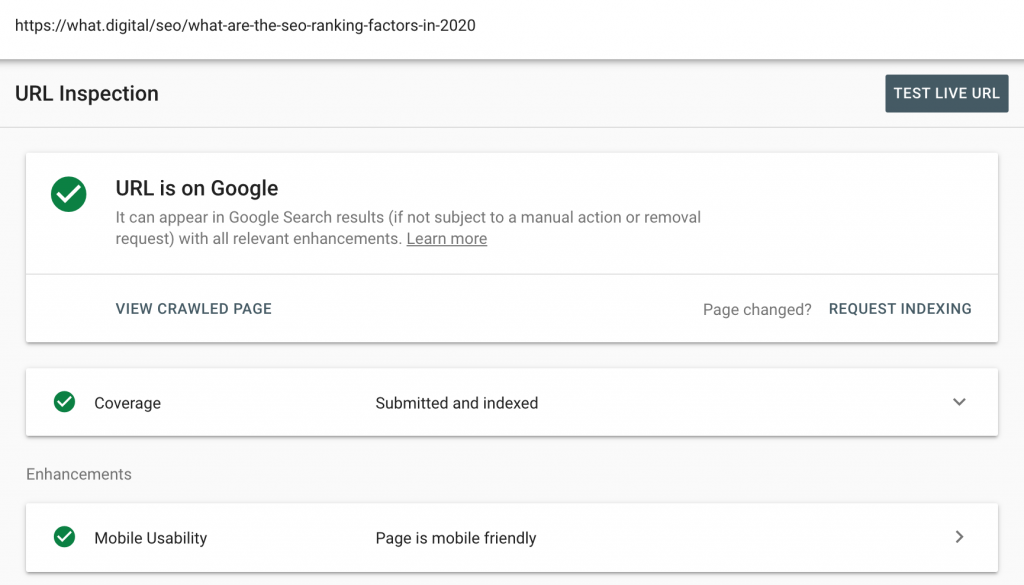
URL in der GSC überprüfen
Die Überprüfung der URL in GSC ist wahrscheinlich das beste Tool, um einen tiefen Einblick in die Indexierungsprobleme zu gewinnen, denn GSC liefert hierbei einen detaillierten Bericht über den aktuellen Status der Seite. Ausserdem kann auch die Live-URL getestet werden, die dann auf die Seite zugreift und sie rendert, was besonders bei der Indexierung von PWA-Seiten nützlich ist.
Benutzerdefinierter Crawl mit Screaming Frog
Screaming Frog ist ein Audit-Tool, das eine Website wie eine Suchmaschine durchsucht und dabei On-Page-Daten sammelt. Das Ziel besteht darin, dem Vermarkter verständliche und nützliche Informationen zu liefern. Indem das Tool viele verschiedene Arten von Fehlern aufspüren kann (z.B. Server- und Link-Fehler, Redirects, von robots.txt blockierte URLs), unterstützt es den Benutzer bei der Identifizierung möglicher Indexierungsprobleme. Ausserdem kann Screaming Frog Seiten crawlen, die gerendert werden müssen (z.B. PWA/JavaScript). Wir haben allerdings festgestellt, dass diese Funktion etwas unzuverlässig ist.
Wie man die Indexierung richtig macht
Indexierungsprobleme überwachen und verstehen
Sorgfältiges Durchlesen der Coverage Reports in GSC ist unbedingt notwendig, um zu verstehen, welche Probleme eine unvollständige Indexierung verursachen können. Sehen wir uns einige der häufigsten Fehlerbehebungen an.
Eine vollständige Sitemap-Datei erstellen
Vergewissere dich, dass deine XML-Sitemap-Datei vollständig ist und zu GSC hinzugefügt wird. Die Sitemap sollte ALLE URLs enthalten, die bei Google aufgelistet werden sollen und dient als Referenzpunkt in Bezug auf wichtige Seiten.
Für eine gültige robots.txt-Datei sorgen
Alle Seiten, die nicht in deiner Sitemap aufgeführt sind, sollten für Suchmaschinen blockiert werden, wie beispielsweise gefilterte Inhalte auf E-Commerce-Seiten, Tags-Seiten oder Seiten mit Duplicate Content. Die Datei Robots.txt ist die effektivste Methode, um Suchmaschinen den Zugriff auf diese unerwünschten Seiten zu verweigern. Allerdings ist beim Bearbeiten und Erstellen der robots.txt-Datei Vorsicht geboten.
Zunächst muss die URL überprüft werden und geklärt werden, ob sie blockiert werden soll. Wenn die Seite absichtlich blockiert wird, kann sie aus der Sitemap entfernt werden. Wenn die Seite nicht blockiert werden soll, müssen die Regeln in der robots.txt-Datei überprüft werden und diejenige Regel, die die Seite blockiert, gefunden und neu geschrieben werden.
Seiten mit noindex-, nofollow-Tags reparieren
Falls die robots.txt-Datei nicht verwendet werden kann, um unerwünschte Seiten zu blockieren (z.B. kein Zugriff auf den Server usw.), kann der noindex-, nofollow-Tag verwendet werden, um Suchmaschinen daran zu hindern, diese Seiten zu durchsuchen. Dies kann entweder durch manuelle Änderung der Webseite oder durch die Umschaltung von noindex auf index in deinem CMS geschehen.
Einzigartige Inhalte bieten und wichtige Tags optimieren
Falls Indexierungsprobleme im Zusammenhang mit Duplicate Content auftreten, besteht die beste Methode darin, Content einzigartig und unverwechselbar zu machen oder zumindest unterschiedliche Meta-Tags für jede Seite einzurichten. Dadurch werden diese Seiten von Suchmaschinen eher als einzigartig erkannt. Der Seiten-Content sollte zudem von hoher Qualität sein und nicht kopiert werden, da er sonst möglicherweise nicht indexiert wird.
Manchmal kommt es auf grossen Websites vor, dass Content nicht gecrawlt und indexiert wird, da er zu tief in der Seitenarchitektur steckt. In diesen Fällen empfiehlt es sich, interne Verlinkungen zu verbessern und die Architektur der Website zu ändern sowie sicherzustellen, dass die Seiten in der Sitemap aufgelistet werden. Ausserdem ist es hilfreich, strukturierte Daten einzusetzen.
URLs kontrollieren und Server-Probleme vermeiden
Achte darauf, dass den Suchmaschinen-Crawlern die richtigen Statuscodes zur Verfügung stehen, d.h. 200 für Seiten, die indexiert werden sollen, 404 für Seiten, die entfernt werden sollen und 301 für Seiten, die umgeleitet wurden. Darüber hinaus gibt es nicht wirklich andere gültige Server-Statuscodes, die verwendet werden sollten.
Indexierung in GSC anfordern
In Fällen von Crawl-Anomalien oder Indexierungsproblemen wird empfohlen, einzelne URLs zu inspizieren und die Ursache zu beseitigen. In manchen Fällen handelt es sich auch um ein vorübergehendes Problem. Dafür bietet Google Tools wie „Fetch as Google“ an, mit dessen Hilfe überprüft wird, ob der Googlebot die Seite derzeit crawlen kann. Zur Diagnose eines bestimmten Fehlers stellt Google eine Liste verschiedener Tools zur Verfügung, die in GSC vorhanden sind. Sobald das Problem identifiziert und behoben wurde, kann die sofortige Indexierung der betroffenen Seite beantragt werden.
JavaScript vermeiden und wenn möglich serverseitiges Rendering verwenden
Um einer Suchmaschine das Lesen einer Seite mit JavaScript zu erleichtern, sind bestimmte Schritte notwendig. Im Wesentlichen gibt es drei Bereiche, die in diesem Prozess berücksichtigt werden müssen: Crawlability (richtige Struktur der Website), Renderability (die Website sollte für Suchmaschinen leicht zu rendern sein) und das Crawl-Budget, das hauptsächlich von der Seitengeschwindigkeit beeinflusst wird. Es gibt Tools wie das URL-Inspektions-Tool, mit denen überprüft werden kann, ob eine Website diese Kriterien erfüllt. Falls Probleme auftreten, können diese Informationen zur Verbesserung der Website genutzt werden. Dabei ist es wichtig zu wissen, dass Suchmaschinen zwar Probleme mit clientseitigem Rendering haben, bei serverseitigem Rendering normalerweise aber gut funktionieren. Aus diesem Grund kann die Implementierung von clientseitigem Rendering zusammen mit dynamischem Rendering, welches offiziell von Google unterstützt wird, die Suchmaschinenoptimierung einer Website unterstützen.
Weitere verwandte SEO-Themen findest du in unserem vollständigen SEO-Guide 2020.